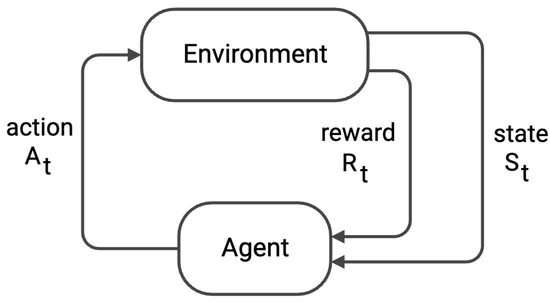
This is what I will be working for a while. Restart is difficult, but necessary.
Why use Reinforcement Learning for Graph coloring?
In my Python application, that works on 3-regular planar graph, deciding which is the order of the edges to remove can be non-trivial. A naive approach randomly picks edges from F2 faces, F3, F4 or F5. This is the approach I used :-(. It leads to impasses when rebuilding the map. See https://4coloring.wordpress.com/2014/08/27/four-color-theorem-experimenting-impasses-as-in-life/
But a reinforcement learning agent can learn to make better selections over time to reduce color conflicts, I hope :-), and shed light on some properties of the graph that can be used in the proof.
The code will be here: https://github.com/stefanutti/maps-coloring-python
Remove one edge at a time from F2, F3, F4, or F5 faces. These faces represent the basic unavoidable set. This process will reduce the map to three faces, including the ocean as the external area. Afterward, I will restore the edges in reverse order, consistently working with 3-regular planar graphs. I will consider Tait coloring of the edges and apply, when necessary, Kempe’s chain color switching to the edges.
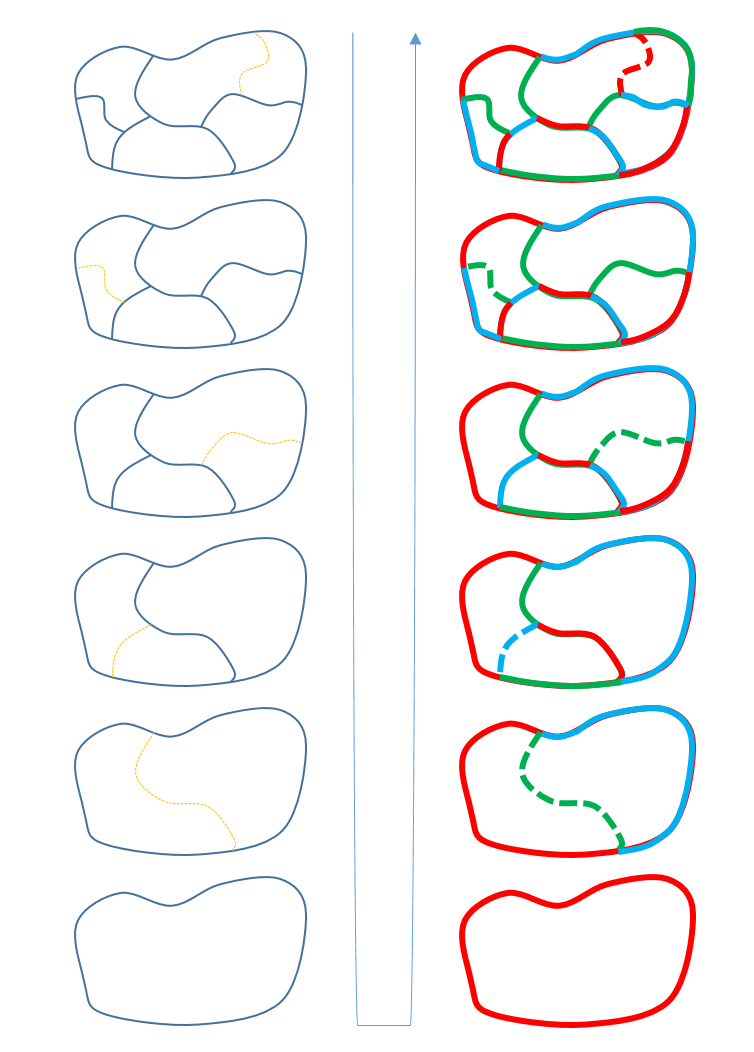
For the Agent:
- Environment initialization = The starting uncolored 3-regular planar graphs
- Action = Select the edge to remove from the 3-regular planar graphs
- State = The updated 3-regular planar graphs
- Reward = +1 if Random Kempe’s chain color switching was not necessary, -1 otherwise